출처 : 변성윤님 블로그.
출처 : 부스트캠프 AI Tech.
1. Logging Basics
1.1 로그란?
- 로그의 어원
- 통나무
- 과거 선박의 속도를 측정하기 위해 칩 로그라는 것을 사용
- 배의 앞에서 통나무를 띄워서 배의 선미까지 도달하는 시간을 재는 방식에 로그를 사용
- 요즘엔 컴퓨터에 접속한 기록, 특정 행동을 한 경우 남는 것을 로그라고 부름

- 데이터는 이제 우리의 삶 어디에서나 존재
- 앱을 사용할 때마다 우리가 어떤 행동을 하는지 데이터가 남음
- 이런 데이터를 사용자 로그 데이터, 이벤트 로그 데이터 등으로 부름
- 위처럼 머신러닝 인퍼런스 요청 로그, 인퍼런스 결과를 저장해야 함
1.2 데이터의 종류
- 데이터베이스 데이터(서비스 로그, Database에 저장)
- 서비스가 운영되기 위해 필요한 데이터
- 예) 고객이 언제 가입했는지, 어떤 물건을 구입했는지 등
- 사용자 행동 데이터(유저 행동 로그, 주로 Object Storage, 데이터 웨어하우스에 저장)
- 유저 로그라고 지칭하면 사용자 행동 데이터를 의미
- 서비스에 반드시 필요한 내용은 아니고, 더 좋은 제품을 만들기 위해 또는 데이터 분석시 필요한 데이터 - 앱이나 웹에서 유저가 어떤 행동을 하는지를 나타내는 데이터
- UX와 관련해서 인터랙션이 이루어지는 관점에서 발생하는 데이터
- 예) Click, View, 스와이프 등
- 인프라 데이터(Metric)
- 백엔드 웹 서버가 제대로 동작하고 있는지 확인하는 데이터 - Request 수, Response 수
- DB 부하 등
- Metric
- 값을 측정할 때 사용
- CPU, Memory 등
- Log
- 운영 관점에서 알아야 하는 데이터를 남길 때 사용
- 함수가 호출되었다. 예외 처리가 되었다 등
- Trace
- 개발 관점에서 알아야하는 것 - 예외 Trace
1.3 저장된 데이터 활용 방식
- “image.jpg”로 마스크 분류 모델로 요청했다
- image.jpg를 중간에 Object Storage에 저장하면 실제로 우리가 볼 때의 실제 Label과 예측 Label을 파악할 수 있음
- “image.jpg” 같은 이름의 이미지로 10번 요청했다
- 같은 이미지로 예측한다고 하면 중간에 저장해서 기존에 예측한 결과를 바로 Return할 수 있겠다(Redis 등을 사용해 캐싱)
- Feature = [[2, 5, 10, 4]] 으로 수요 예측 모델로 요청했다
- 어떤 Feature가 들어오는지 알 수 있고, Feature를 사용할 때 모델이 어떻게 예측하는지 알 수 있음
- 궁극적으로 현재 시스템이 잘 동작하는지 알 수 있음
- 데이터가 저장되어 있지 않다면
- 과거에 어떤 예측을 했는지 알 수 없음
- print 문의 로그를 저장한 곳을 찾아서 확인해야 함(Linux 서버에 접속하거나)
- 모델이 더 발전하기 위한 개선점을 찾기 어려움
- 현재 시스템이 잘 동작하고 있는지 알기 어려움
1.4 데이터 적재 방식
1.4.1 Database(RDB)에 저장하는 방식
- 다시 웹, 앱 서비스에서 사용되는 경우 활용
- 실제 서비스용 Database
- 관계형 데이터베이스(Relational Database)
- 행과 열로 구성
- 데이터의 관계를 정의하고, 데이터 모델링 진행
- 비즈니스와 연관된 중요한 정보
- 예) 고객 정보, 주문 요청
- 영구적으로 저장해야 하는 것은 데이터베이스에 저장 - 데이터 추출시 SQL 사용
- MySQL, PostgreSQL 등
1.4.2 Database(NoSQL)에 저장하는 방식
- Elasticsearch, Logstash or Fluent, Kibana에서 활용하려는 경우
- 스키마가 Strict한 RDBMS와 다르게 스키마가 없거나 느슨한 스키마만 적용
- Not Only SQL
- 데이터가 많아지며 RDBMS로 트래픽을 감당하기 어려워서 개발됨
- 일반적으로 RDBMS에 비해 쓰기와 읽기 성능이 빠름
- Key Value Store, Document, Column Family, Graph 등
- JSON 형태와 비슷하며 XML 등도 활용됨
{ key : value, key2 : {key2-1:value21, key2-2:value22} }- MongoDB

1.4.3 Object Storage에 저장하는 방식
- S3, Cloud Storage에 파일 형태로 저장
- csv, parquet, json 등
- 별도로 Database나 Data Warehouse로 옮기는 작업이 필요
- 어떤 형태의 파일이여도 저장할 수 있는 저장소
- AWS S3, GCP Cloud Storage 등
- 특정 시스템에서 발생하는 로그를 xxx.log에 저장한 후, Object Storage에 저장하는 형태
- 비즈니스에서 사용되지 않는 분석을 위한 데이터
- 이미지, 음성 등을 저장
1.4.4 Data Warehouse에 저장하는 방식
- 데이터 분석시 활용하는 데이터 웨어하우스로 바로 저장
- 여러 공간에 저장된 데이터를 한 곳으로 저장
- 데이터 창고
- RDBMS, NoSQL, Object Storage 등에 저장된 데이터를 한 곳으로 옮겨서 처리
- RDBMS와 같은 SQL을 사용하지만 성능이 더 좋은 편
- AWS Redshift, GCP BigQuery, Snowflake 등
1.5 데이터 적재 요약
- 정말 다양한 방법으로 데이터를 저장할 수 있음
- 상황에 따라 다르지만, 여기선 Serving 과정에서 데이터를 기록하기 위함
- 상황
- 데이터 분석은 BigQuery에서 진행
- 해당 로그는 애플리케이션과 상관없음
- 사용 가능 대안
- 파이썬 로깅 모듈을 사용해 CSV로 저장해서 Cloud Storage에 업로드
- BigQuery로 바로 데이터 추가
2. Logging in Python
2.1 Python Logging Module
- 파이썬 기본 모듈, logging
- 웹서버, 머신러닝, CLI 등 여러 파이썬 코드에서 사용할 수 있음
- 심각도에 따라 info, debug, error, warning 등 다양한 카테고리로 데이터를 저장할 수 있음

- Log Level
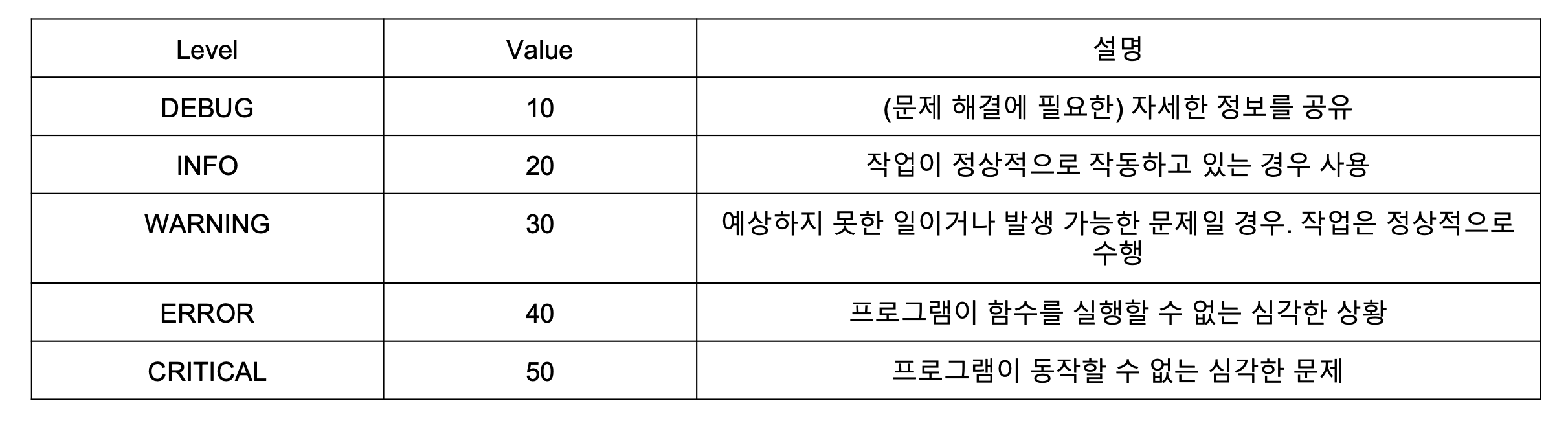
- 기본 Logging Level은 WARNING
- 설정하지 않으면 WARNING보다 심각한 레벨의 로그만 보여줌
- logging vs print
- console에만 output을 출력하는 print
- logging은 file, websocket 등 파이썬이 다룰 수 있는 모든 포맷으로 output을 출력할 수 있음
- 언제 어디서(파일 이름과 코드 상의 몇번째 줄인지) 해당 output이 발생했는지 알 수 있음
- output을 심각도에 따라 분류할 수 있음
- 예) Dev 환경에서는 debug 로그까지, Prod(운영) 환경에서는 info 로그만 보기 등)
- 다만 print보다 알아야 하는 지식이 존재

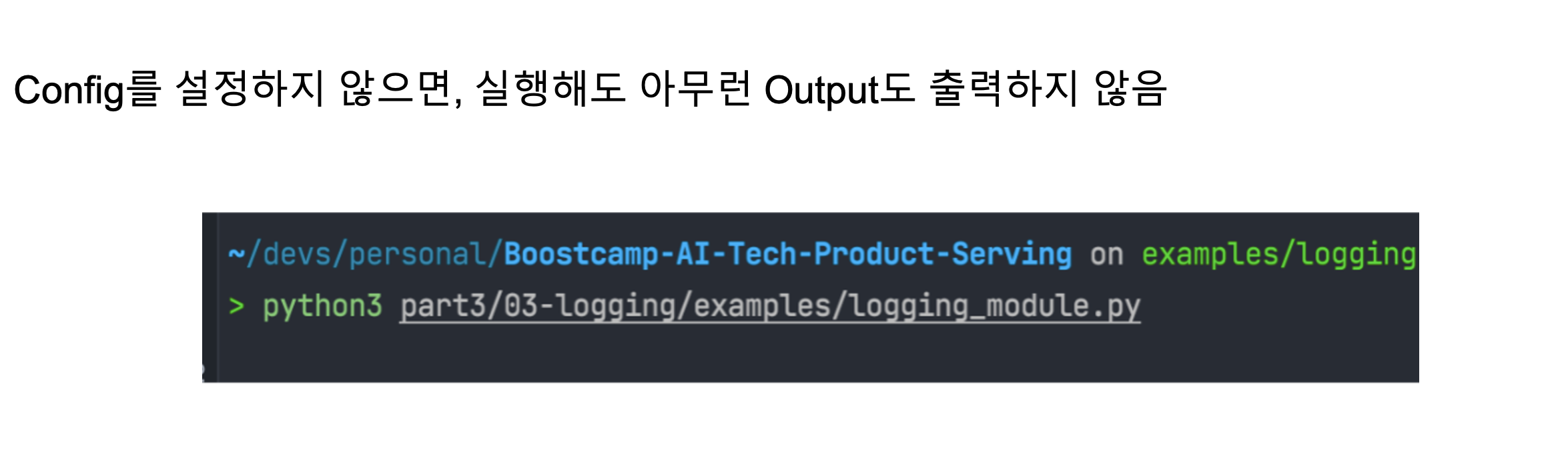
- Console에서 해당 output을 확인하려면 logging config를 지정해야 함
- 위에서 지정한 포맷('%(asctime)s | %(levelname)s - %(message)s') 형태로 로그가 출력됨
- logging 모듈에서 제공하는 정보는 아래 링크에서 확인할 수 있음(asctime, levelname 등)
- https://docs.python.org/3/library/logging.html#logrecord-attributes
- 아래와 같이 json 으로 관리하는게 편함
- 참조 : https://fangpenlin.com/posts/2012/08/26/good-logging-practice-in-python/
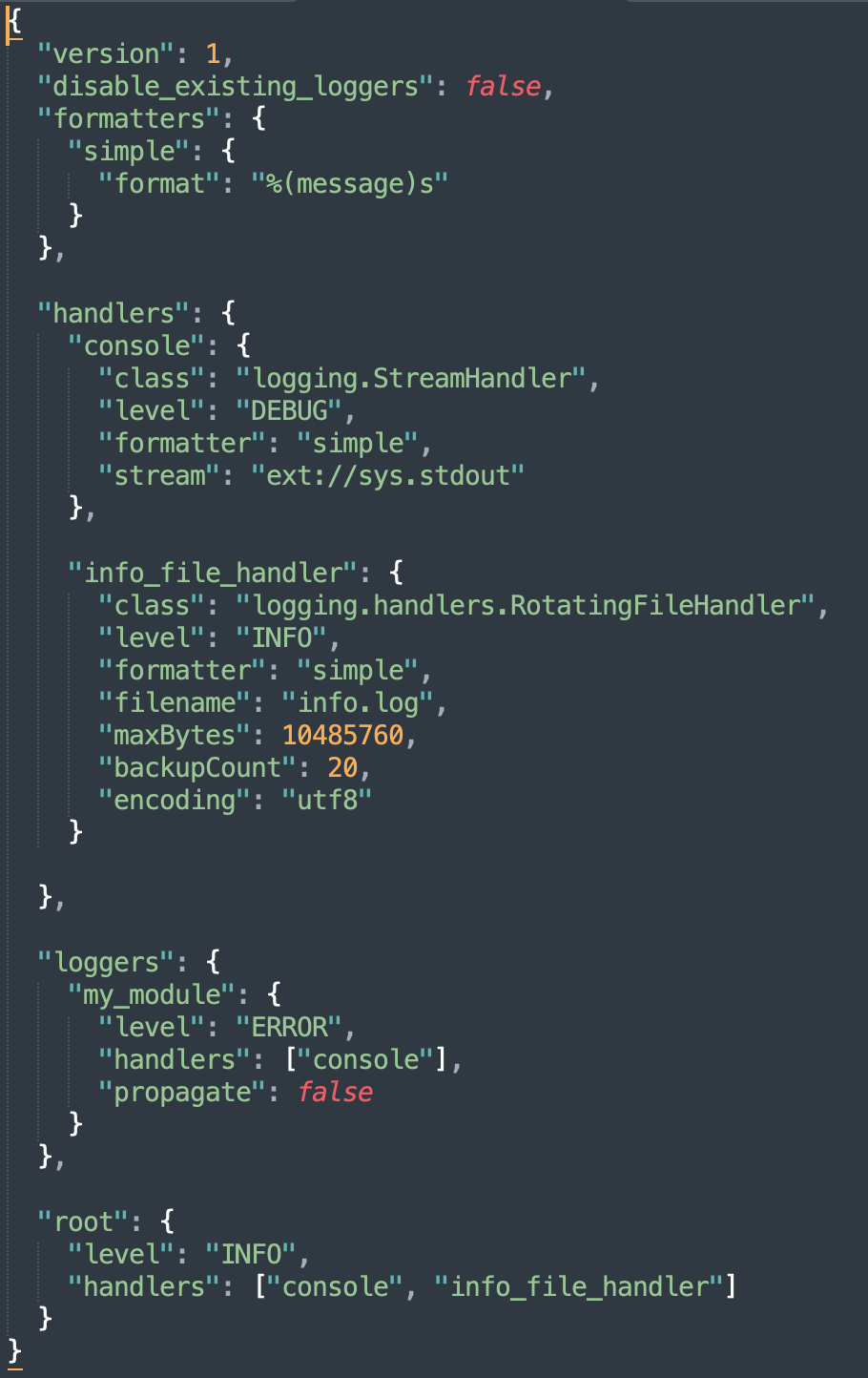
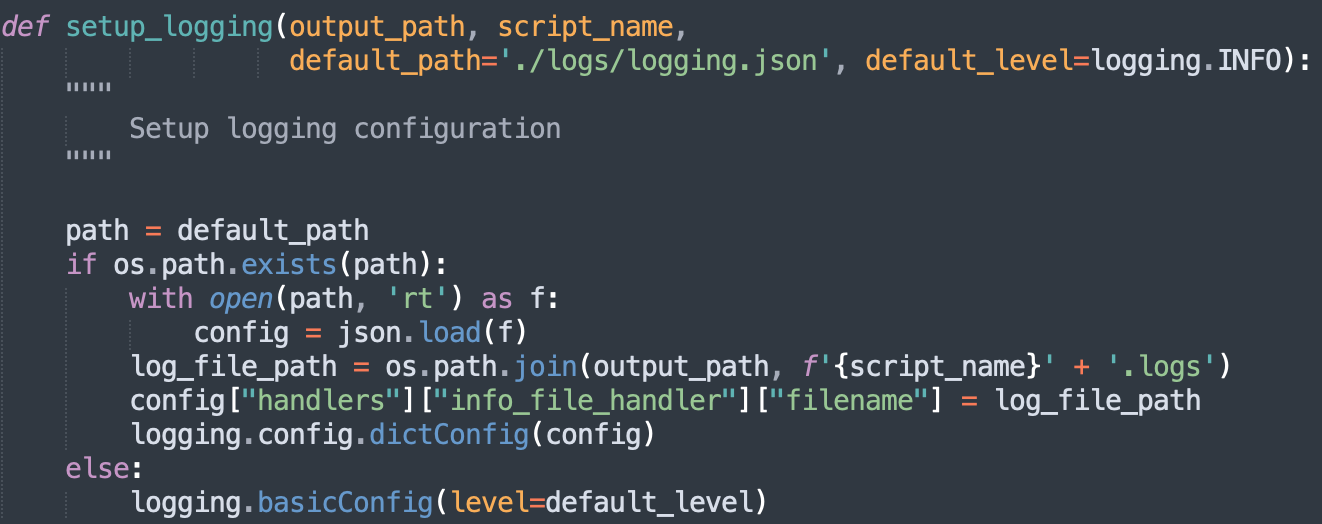

2.2 Python Logging Component
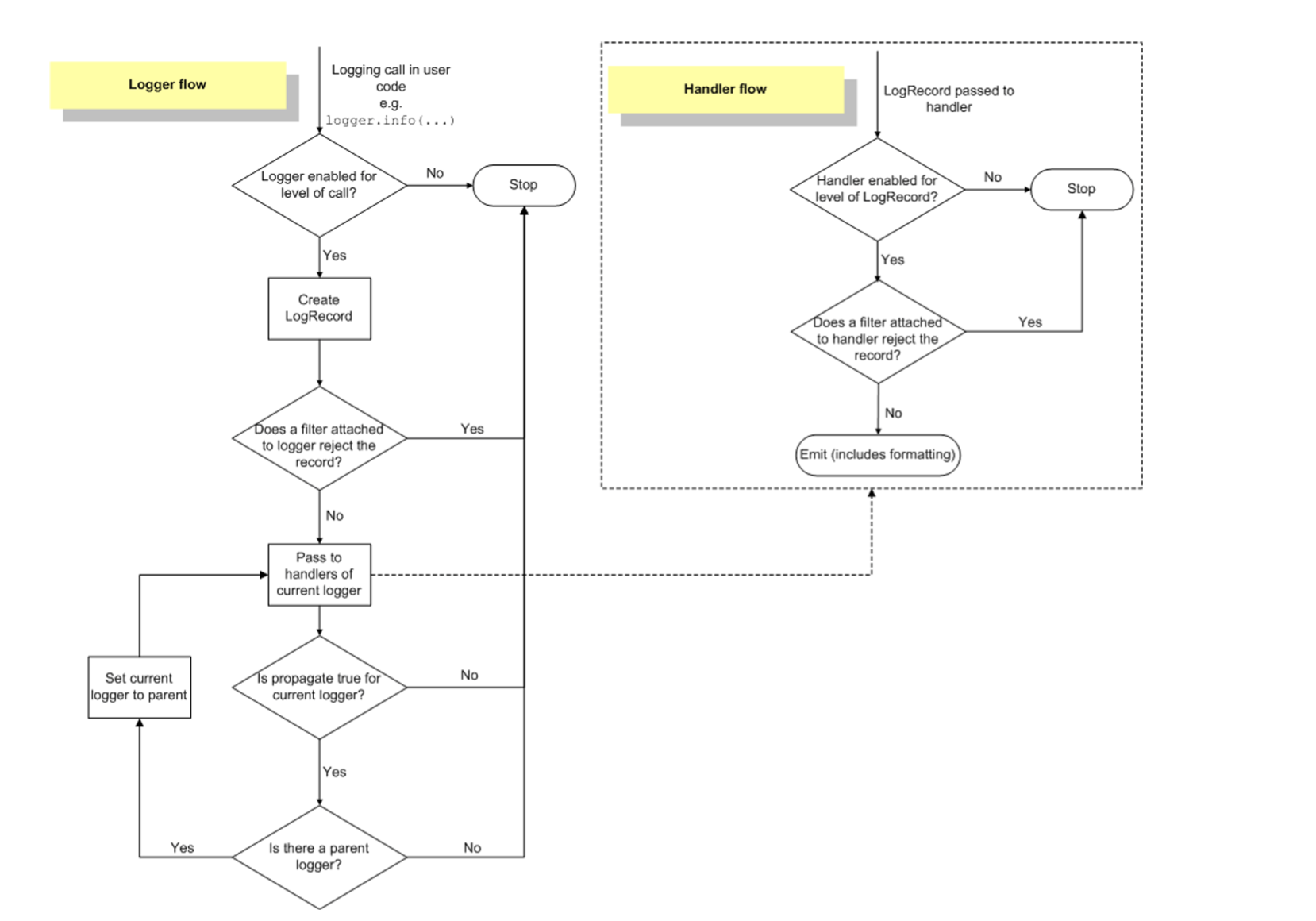
2.2.1. Loggers
- 로그를 생성하는 Method 제공(logger.info() 등)
- 로그 Level과 Logger에 적용된 Filter를 기반으로 처리해야 하는 로그인지 판단
- Handler에게 LogRecord 인스턴스 전달
- logging.getLogger(name)으로 Logger Object 사용
- name이 주어지면 해당 name의 logger 사용하고, name이 없으면 root logger 사용
- 마침표로 구분되는 계층 구조
- logging.getLogger(‘foo.bar’) => logging.getLogger(‘foo’)의 자식 logger 반환
- logging.setLevel() : Logger에서 사용할 Level 지정
2.2.2 Handlers
- Logger에서 만들어진 Log를 적절한 위치로 전송(파일 저장 또는 Console 출력 등)
- Level과 Formatter를 각각 설정해서 필터링 할 수 있음
- StreamHandler, FileHandler, HTTPHandler 등
2.2.3 Filters
2.2.4 Formatters
- 최종적으로 Log에 출력될 Formatting 설정
- 시간, Logger 이름, 심각도, Output, 함수 이름, Line 정보, 메시지 등 다양한 정보 제공
2.5 Logging Flow
3. Online Serving Logging(BigQuery)
- BigQuery에 Online Serving Input과 Output 로그 적재
- 빅쿼리 테이블을 세팅합니다
- 빅쿼리에 적재하기 쉽게 JSON 형태로 로그를 정제 -> pythonjsonlogger를 사용
- python logging 모듈을 사용해서 빅쿼리에(실시간) 로그 적재(file과 console에도 남을 수 있도록 handler를 지정)
- BigQuery
- Google Cloud Platform의 데이터 웨어하우스
- 데이터 분석을 위한 도구로 Apache Spark의 대용으로 활용 가능
- Firebase, Google Analytics 4와 연동되어 많은 회사에서 사용 중
3.1 BigQuery 데이터 구조
- GCP의 Project 내부에 BigQuery의 리소스가 존재
- Dataset, Table, View 등
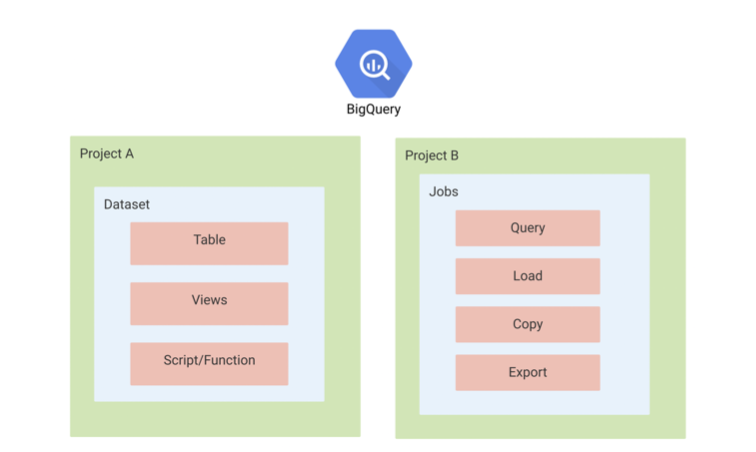
- Dataset, Table, View 등
3.2 BigQuery 데이터세트 만들기
- [Product Serving] 3-3. Logging.pdf
3.3 BigQuery 테이블 만들기
- [Product Serving] 3-3. Logging.pdf
3.4 BigQuery로 실시간 로그 데이터 수집하기
- [Product Serving] 3-3. Logging.pdf
IAM Error Fix 참고하여 설정
- [Product Serving] 3-2. Docker.pdf
'MLOps' 카테고리의 다른 글
| MLOps - 18. BentoML (0) | 2022.06.02 |
|---|---|
| MLOps - 17. MLFlow (0) | 2022.06.01 |
| MLOps - 15. Docker (0) | 2022.05.30 |
| MLOps - 14. FastAPI (0) | 2022.05.29 |
| MLOps - 13. FastAPI (0) | 2022.05.28 |




댓글