Abstract
What is Multi-hop retrieval?
- Task of retrieving a series of multiple documents that together provide sufficient evidence to answer a natural language query.
Problems to solve
- Number of hops increases -> reformulated query (usually concatenation of previous retrieval & query) increasingly depends on the documents retrieved in its previous hops
- it further tigthens the embedding bottleneck of the query vector
- it becomes more prone to error propagation
Solutions
- bi-encoder approach -> generative approach
- how? instead of retriving documents, generating the entire text seqeunce(documents)
- Searching evidence in model's parametric space rather than in L2, inner product space
Results
- higher performance than bi-encoder models in five datasets
- superior GPU memory and storage.
Intro
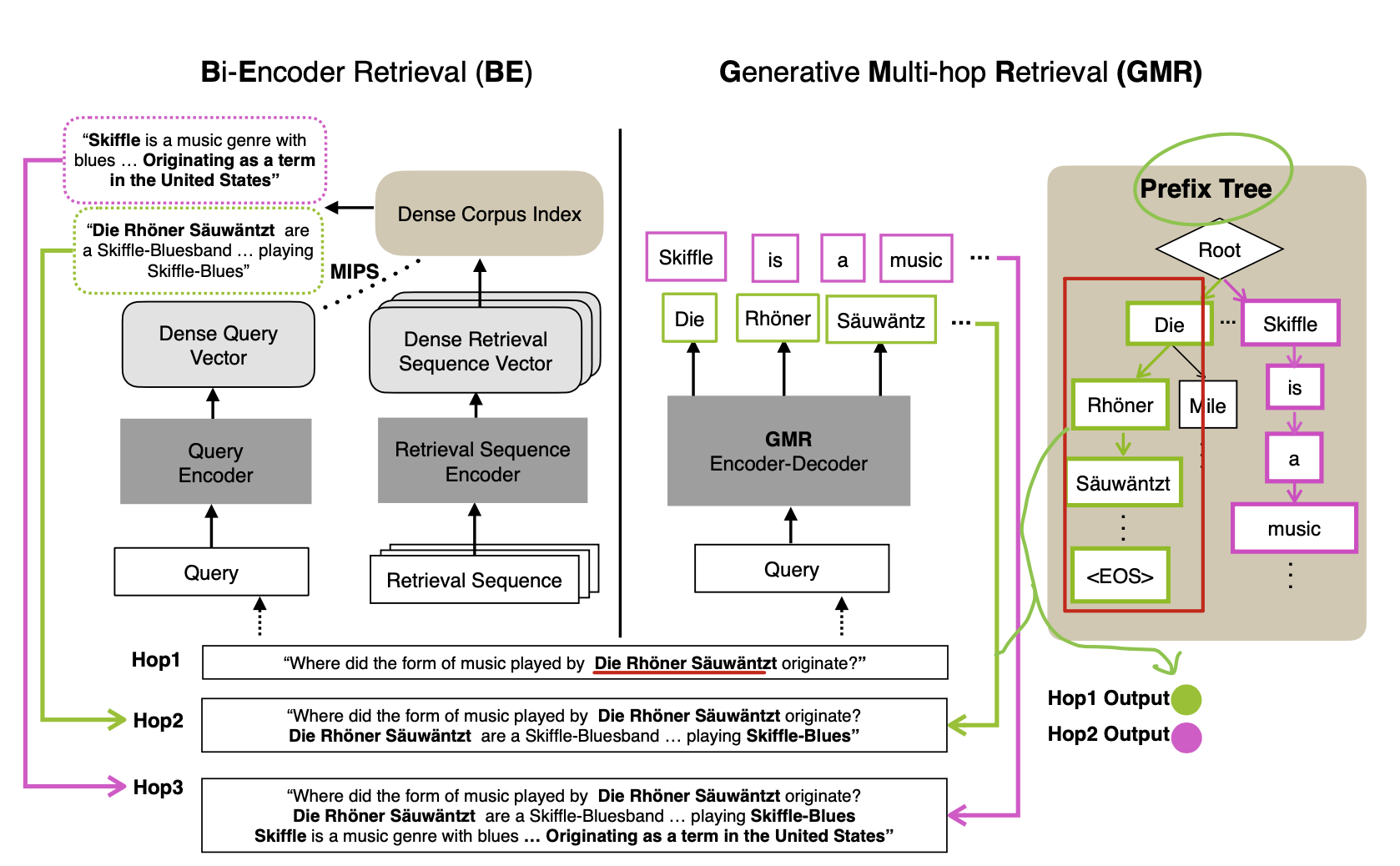
- biencoder architecture is not suitable for multi-hop retrieval
- as performance degrades as the number of hops increase
- vulnerable to error propagation
- GMR is robust in multi-hop retrival setting
- shows high performance in 5 datasets
- especially in the case of real world scenario where there is low unseen rate
- adapts multi-hop memorization
- effectively memorize target corpus
- enhances the performance of GMR
Related Work
Multi-hop Retrieval
- bi-encoder shows on canonical Text Retrieval (= no hop retrieval)
- extending bi-encoder to multip-hop stteing has shown good performance
- but suffering from information loss when condensing the text into a fixed-size vector
Generative Retrieval
- GENRE(Generative Entitiy REtrieval) achieves comparable or higher performance on entity retrieval tasks than bi-encoder models
- suggesting generative retriever cross-encodes the input and output efficiently, capturing the relationship between the two wihout information loss due to its autoregressive formulation.
- SEAL (Search Engines with Autoregressive LMs) outperform well-designed bi-endcoder models (DPR, GAR)
Generative Multi-hop Retrieval
LM memorization
- TLDR; pre-training on the given text corpus (unconditional generation)
Multi-hop memorization
- TLDR; training on the format (conditional generation task)
- step1. Training query generation model
- step2. Sample multiple sets of retrieval sequences from a given target corpus
a. contruct graph with the target corpus
b. Sample subgraphs by iterating through retrieval seqeunes, which are used as input to the query generator
c. Sampled retrival sequences given as inputs to query generation model to generate pseudo queries - step3. Using pseudo-multi-hop quries and sampled subgraphs(retrival sequences) to multi-hop retrieval training dataset as input and output and together used to train GMR
Experimental Setup
Fixed and Dynamic Multi-hop Retrieval
- Fixing the number of hops
- Model dynamically set the number of hops using DONE token
- Dynamic setting shows higher f1-score at each f1@k when k = 5, 10, 20
Datasets
- HotpotQA
- Entailment TreeBank (EntailBank)
- StrategyQA
- RuleTaker-Open
- Explagraphs-Open
Bi-Encoder mdoels
- MDR (extends DPR to multi-hop setting)
- ST5 (Sentence T5) bi-encoder retrieval model using T5
- uses the first decoder output as the sequence embedding
Eval Metric
- fixed multi-hop -> retrieval seauence recall following the evalutaion metric of MDR
- varing multi-hop -> retrieval sequence recall rate(R@k) of each query and average over the number of queries
- dynamic multi-hop -> mseaure retrieval seqeunce f1 score(F1@K)
Experimental Results
Results
- GMR outperforms on EntailTree, StrategyQA, Explagraph-Open
- HotpotQA, MDR scores higher
- techniques such as hard negative training, memory bank are nontrivial
- HotpotQA is fixed to 2 hops, relatively short
- suffer less from bottleneck & error propagation problems
- MDR gets wrong by failing to retrieve the second hop target even though the first hop prediction is correct
- GMR mostly gets wrong when the first-hop target is not explicitly expressed in the query.
- RuleTaker-Open
- task is to contruct a reasonsing graph by dynamic retrieval setting
- GMR constructs more complex and diverse reasoning graphs by the retrieval process
- suggesting GMR is more powerful in highly structured items such as reasonsing chains and graph relations.
- Importance of Explicit Generation in Multi-hop Retrival Task
- Previous works like GENRE, DSI are not directly applicable to multi-hop retrieval tasks
- Difficulty of expanding to a larger corpus set in DSI unlike GMR
Analysis
Limitations of Bi-Encoder Model
- bottleneck problem
- performance of bi-encoder model consistently decreases as the number of hops increases (the number of sequences added to initail input query increases)
- error propagations
- the bi-encoder approach is more vulnerable to error propagations than generative retrieval approach.
Effect of Unseen Rage of GMR
- high unseen rate -> relatively lower performance than in low unseen rate
- LM memorization : pre-training using dataset using no-hop retrival object function -> applied to any daset
- multi-hop memorization : generating pseudo multi-hop quries by constructin subgraphs (retrival sequences) -> not applicable any dataset
Storage, Inference Time of GMR
- BE -> create large index embeddings and stores it on GPU
- GMR -> only needs to build prefix tree (as in GENRE)
- GMR optim 100times faster & 79.5% less GPU memeory
- With early stopping, 40% inference time reductions
- total starage 70.2% less compared to MDR
'AI > NLP' 카테고리의 다른 글
| FM-index part2. FM-index (0) | 2022.09.16 |
|---|---|
| FM-index part1. BWT (Burrows Wheeler Transformation) (0) | 2022.09.15 |
| Prompt Injection: Parameterization of Fixed Inputs (0) | 2022.08.22 |
| Fusion In Decoder : Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering (0) | 2022.06.23 |
| DPR: Dense Passage Retrieval for Open-Domain Question Answering (0) | 2022.05.02 |



댓글