Improving Language Understanding by Generative Pre-Training
Paper : Link
Code : Link
Description : GPT1
Abstract
Motivation (Background of Study)
- Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately.
Achievement (Research Result)
- We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task.
- Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task
Impact (Significance of Study)
- In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture.
1. Introduction
Pros in using unlabeled data
- models that can leverage linguistic information from unlabeled data provide a valuable alternative to gathering more annotation, which can be time-consuming and expensive.
- Further, even in cases where considerable supervision is available, learning good representations in an unsupervised fashion can provide a significant performance boost.
Hurdles using unlabeled data
- First, it is unclear what type of optimization objectives are most effective at learning text representations that are useful for transfer.
- Second, there is no consensus on the most effective way to transfer these learned representations to the target task.
Research Objective
- Our goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks.
- Explore a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning
Research Outline
- Model architecture : Transformer - more structured memory for handling long-term dependencies in text, compared to alternatives like recurrent networks, resulting in robust transfer performance across diverse tasks
- Fine-tuning : utilize task-specific input adaptations derived from traversal-style approaches, which process structured text input as a single contiguous sequence of tokens
Research Result
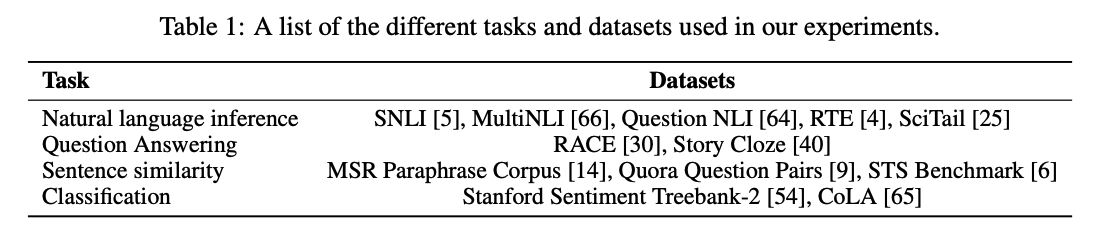
- four types of language understanding tasks – natural language inference, question answering, semantic similarity, and text classification
- Our general task-agnostic model outperforms discriminatively trained models that employ architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied
2. Related Work
Semi-supervised learning for NLP
- The earliest approaches : compute
word-level or phrase-level statistics, which were then used as features in a supervised model - Using
word embeddings, which are trained on unlabeled corpora, to improve performance on a variety of tasks. These approaches, however, mainly transfer word-level information, whereas we aim to capture higher-level semantics Phrase-level or sentence-level embeddings, which can be trained using an unlabeled corpus, have been used to encode text into suitable vector representations for various target tasks
Unsupervised pre-training (& Differentiations)
- Unsupervised pre-training is a special case of semi-supervised learning where the goal is to find a good initialization point instead of modifying the supervised learning objective.
- transformer networks allows us to capture longerrange linguistic structure
- effectiveness of our model on a wider range of tasks including natural language inference, paraphrase detection and story completion
- require minimal changes to our model architecture during transfer, whereas other approaches use hidden representations from a pre-trained language or machine translation model as auxiliary features while training a supervised model on the target task.
Auxiliary training objectives
- Adding auxiliary unsupervised training objectives is an alternative form of semi-supervised learning.
- Our experiments also use an auxiliary objective, but as we show, unsupervised pre-training already learns several linguistic aspects relevant to target tasks.
3. Framework
- first stage is learning a high-capacity language model on a large corpus of text
- fine-tuning stage, where we adapt the model to a discriminative task with labeled data.
3.1 Unsupervised pre-training


3.2 Supervised fine-tuning.

3.3 Task-specific input transformations

- For some tasks, like text classification, we can directly fine-tune our model as described above.
- Certain other tasks, like question answering or textual entailment, have structured inputs such as ordered sentence pairs, or triplets of document, question, and answers.
- Since our pre-trained model was trained on contiguous sequences of text, we require some modifications to apply it to these tasks.
- traversal-style approach , where we convert structured inputs into an ordered sequence that our pre-trained model can process. These input transformations allow us to avoid making extensive changes to the architecture across tasks.
Textual entailment
- concatenate the premise p and hypothesis h token sequences, with a delimiter token ($) in between
Similarity
- we modify the input sequence to contain both possible sentence orderings (with a delimiter in between) and process each independently to produce two sequence representations which are added element-wise before being fed into the linear output layer.
Question Answering and Commonsense Reasoning
- We concatenate the document context and question with each possible answer, adding a delimiter token in between to get [z; q; $; ak].
- Each of these sequences are processed independently with our model and then normalized via a softmax layer to produce an output distribution over possible answers.
4. Experiments
4.1 Setup
- Unsupervised pre-training
- We use the
BooksCorpus datasetfor training the language model. - Our language model achieves a very low token level
perplexity of 18.4on this corpus.
- We use the
- Model specifications
- Trained a
12-layer decoder-only transformer with masked self-attention heads (768 dimensional states and 12 attention heads) - For the position-wise feed-forward networks
3072 dimensional inner states. Adam optimization scheme with a max learning rate of 2.5e-4.- The learning rate was
increased linearly from zero over the first 2000 updatesandannealed to 0 using a cosine schedule. - We train for
100 epochs on minibatches of 64 randomly sampled, contiguoussequences of 512 tokens. layernormis used extensively throughout the model, asimple weight initialization of N(0, 0.02)was sufficient.- We used a
bytepair encoding (BPE) vocabulary with 40,000 merges residual, embedding, and attention dropouts with a rate of 0.1 for regularization- We also employed a
modified version of L2 regularizationproposed in [37], withw = 0.01 on all non bias or gain weights. - For the activation function, we used the
Gaussian Error Linear Unit (GELU) - We used learned
position embeddingsinstead of the sinusoidal version proposed in the original work. - We use the ftfy library2 to clean the raw text in BooksCorpus, standardize some punctuation and whitespace, and use the spaCy tokenizer.3
- Trained a
- Fine-tuning details
- reuse the hyperparameter settings from unsupervised pre-training.
- add
dropout to the classifier with a rate of 0.1 learning rate of 6.25e-5and abatchsize of 32.- finetunes quickly and
3 epochs of training was sufficientfor most cases. - We use a
linear learning rate decay schedule with warmup over 0.2% of training. λ was set to 0.5.
4.2 Supervised fine-tuning
- Natural Language Inference

- judging the relationship between them from one of entailment, contradiction or neutral
- Question answering and commonsense reasoning

- task that requires aspects of single and multi-sentence reasoning is question answering
- Semantic Similarity & Classification
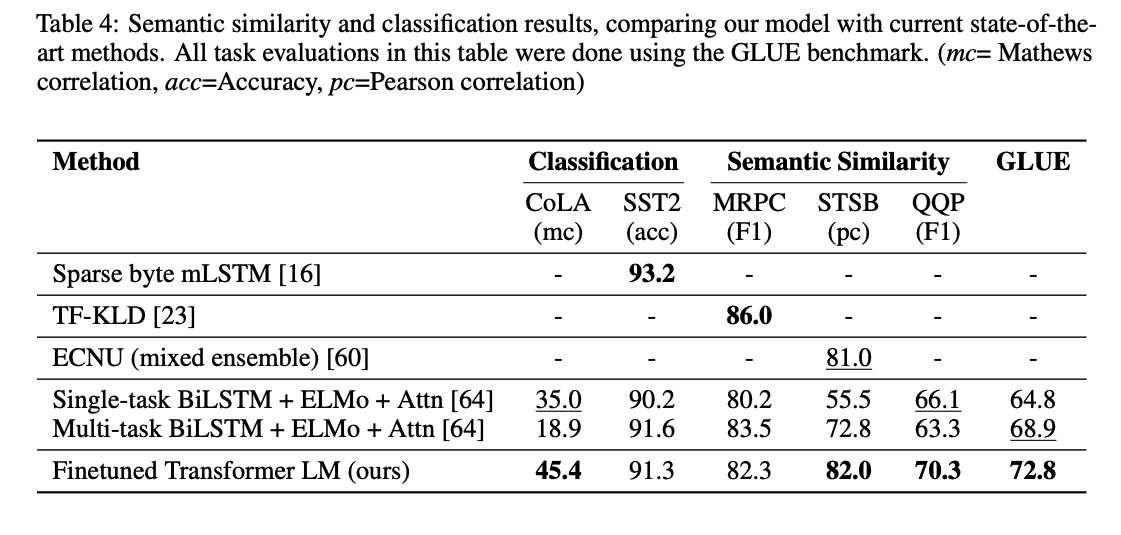
- Semantic similarity (or paraphrase detection) tasks involve predicting whether two sentences are semantically equivalent or not
5. Analysis
- Impact of number of layers transferred
- We observe the standard result that transferring embeddings improves performance and that each transformer layer provides further benefits up to 9% for full transfer on MultiNLI.
- This indicates that each layer in the pre-trained model contains useful functionality for solving target tasks.
- Zero-shot Behaviors
- suggesting that generative pretraining supports the learning of a wide variety of task relevant functionality.
- We also observe the LSTM exhibits higher variance in its zero-shot performance suggesting that the inductive bias of the Transformer architecture assists in transfer.

- Ablation studies

- larger datasets benefit from the auxiliary objective but smaller datasets do not
- observe a 5.6 average score drop when using the LSTM instead of the Transformer
- the lack of pre-training hurts performance across all the tasks, resulting in a 14.8% decrease compared to our full model
6. Conclusion
- By pre-training on a diverse corpus with long stretches of contiguous text
- acquires significant world knowledge and ability to process long-range dependencies
- successfully transferred to solving discriminative tasks
- Our work suggests that achieving significant performance gains is indeed possible, and offers hints as to what models (Transformers) and data sets (text with long range dependencies) work best with this approach




댓글