BART: A Robustly Optimized BERT Pretraining Approach
Paper : https://arxiv.org/pdf/1910.13461.pdf
Abstract
BART
- a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by
- corrupting text with an arbitrary noising function
- learning a model to reconstruct the original text
- uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing
- BERT (due to the bidirectional encoder)
- GPT (with the left-to-right decoder)
- many other more recent pretraining schemes
- evaluate a number of noising approaches
- randomly shuffling the order of the original sentences
- using a novel in-filling scheme
- spans of text are replaced with a single mask token
Achievement (Research Result)
- matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD
- achieves new stateof-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE
- BART also provides a 1.1 BLEU increase over a back-translation system for machine translation, with only target language pretraining
- We also report ablation experiments that replicate other pretraining schemes within the BART framework, to better measure which factors most influence end-task performance
1. Introduction
Masked language models
- denoising autoencoders that are trained to reconstruct text where a random subset of the words has been masked out
- Recent work has shown gains by improving the distribution of masked tokens
- the order in which masked tokens are predicted
- the available context for replacing masked tokens
- However, these methods typically focus on particular types of end tasks (e.g. span prediction, generation, etc.), limiting their applicability
BART
- We present BART, which pre-trains a model combining Bidirectional and Auto-Regressive Transformers.
- BART is a denoising autoencoder built with a sequence-to-sequence model that is applicable to a very wide range of end tasks
- Pretraining
- text is corrupted with an arbitrary noising function,
- a sequence-to-sequence model is learned to reconstruct the original text
- uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing
- BERT (due to the bidirectional encoder)
- GPT (with the left-to-right decoder)
- many other more recent pretraining schemes
Advantage of BART setup

- A key advantage of this setup is the noising flexibility;
- arbitrary transformations can be applied to the original text,
- including changing its length
- We evaluate a number of noising approaches, finding the best performance by both
- randomly shuffling the order of the original sentences
- using a novel in-filling scheme
- where arbitrary length spans of text (including zero length) are replaced with a single mask token.
- This approach generalizes the original word masking and next sentence prediction objectives in BERT by forcing the model to reason more about overall sentence length and make longer range transformations to the input
BART achievements
- BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks
- matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD
- achieves new stateof-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE
- BART also opens up new ways of thinking about fine tuning
- We present a new scheme for machine translation where a BART model is stacked above a few additional transformer layers
- These layers are trained to essentially translate the foreign language to noised English, by propagation through BART, thereby using BART as a pre-trained target-side language model. This approach improves performance over a strong back-translation MT baseline by 1.1 BLEU on the WMT Romanian-English benchmark
2. Model
2.1 Architecture
- BART uses the standard sequence-to-sequence Transformer architecture from (Vaswani et al., 2017)
- Following GPT, that we modify ReLU activation functions to GeLUs (Hendrycks & Gimpel, 2016) and initialise parameters from N (0, 0.02)
- For our base model, we use 6 layers in the encoder and decoder
- For our large model we use 12 layers in each
- The architecture is closely related to that used in BERT, with the following differences:
- Each layer of the decoder additionally performs cross-attention over the final hidden layer of the encoder (as in the transformer sequence-to-sequence model)
- BERT uses an additional feed-forward network before wordprediction, which BART does not. In total, BART contains roughly 10% more parameters than the equivalently sized BERT model.
2.1 Pre-training BART
- BART is trained by corrupting documents and then optimizing a reconstruction loss—the cross-entropy between the decoder’s output and the original document
- Unlike existing denoising autoencoders, which are tailored to specific noising schemes, BART allows us to apply any type of document corruption. In the extreme case, where all information about the source is lost, BART is equivalent to a language model.
- experiment with several previously proposed and novel transformation

- Token Masking : Following BERT (Devlin et al., 2019), random tokens are sampled and replaced with [MASK] elements
- Token Deletion : Random tokens are deleted from the input. In contrast to token masking, the model must decide which positions are missing inputs
- Text Infilling :
- A number of text spans are sampled, with span lengths drawn from a Poisson distribution (λ = 3)
- Each span is replaced with a single [MASK] token.
- 0-length spans correspond to the insertion of [MASK] tokens.
- Text infilling is inspired by SpanBERT (Joshi et al., 2019), but SpanBERT samples span lengths from a different (clamped geometric) distribution, and replaces each span with a sequence of [MASK] tokens of exactly the same length.
- Text infilling teaches the model to predict how many tokens are missing from a span
- Sentence Permutation : A document is divided into sentences based on full stops, and these sentences are shuffled in a random order.
- Document Rotation : A token is chosen uniformly at random, and the document is rotated so that it begins with that token. This task trains the model to identify the start of the document
3. Fine-tuning BART
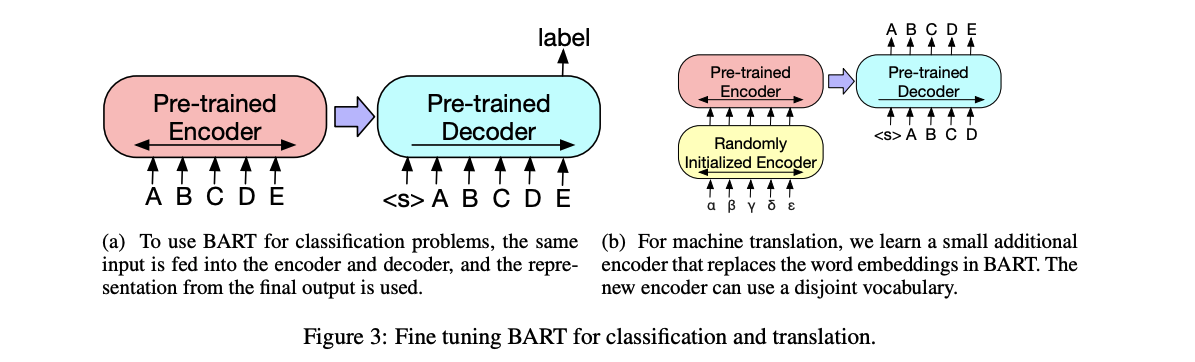
3.1 Sequence Classification Tasks
- For sequence classification tasks, the same input is fed into the encoder and decoder, and the final hidden state of the final decoder token is fed into new multi-class linear classifier.
- This approach is related to the CLS token in BERT;
- however we add the additional token to the end so that representation for the token in the decoder can attend to decoder states from the complete input
3.2 Token Classification Tasks
- For token classification tasks, such as answer endpoint classification for SQuAD
- we feed the complete document into the encoder and decoder
- use the top hidden state of the decoder as a representation for each word
- This representation is used to classify the token.
3.3 Sequence Generation Tasks
- Because BART has an autoregressive decoder, it can be directly fine tuned for sequence generation tasks such as abstractive question answering and summarization.
- In both of these tasks, information is copied from the input but manipulated, which is closely related to the denoising pre-training objective.
- Here, the encoder input is the input sequence, and the decoder generates outputs autoregressively.
3.3 Machine Translation
- Previous work Edunov et al. (2019) has shown that models can be improved by incorporating pre-trained encoders, but gains from using pre-trained language models in decoders have been limited.
- We show that it is possible to use the entire BART model (both encoder and decoder) as a single pretrained decoder for machine translation, by adding a new set of encoder parameters that are learned from bitext
- More precisely, we replace BART’s encoder embedding layer with a new randomly initialized encoder.
- The model is trained end-to-end, which trains the new encoder to map foreign words into an input that BART can de-noise to English.
- The new encoder can use a separate vocabulary from the original BART model.
- We train the source encoder in two steps, in both cases backpropagating the cross-entropy loss from the output of the BART model.
- In the first step, we freeze most of BART parameters and only update the randomly initialized source encoder, the BART positional embeddings, and the self-attention input projection matrix of BART’s encoder first layer.
- In the second step, we train all model parameters for a small number of iterations
4. Comparing Pre-training Objectives
4.1 Comparison Objectives
- Language Model
- Similarly to GPT (Radford et al., 2018), we train a left-to-right Transformer language model. This model is equivalent to the BART decoder, without cross-attention.
- Permuted Language Model
- Based on XLNet (Yang et al., 2019), we sample 1/6 of the tokens, and generate them in a random order autoregressively. For consistency with other models, we do not implement the relative positional embeddings or attention across segments from XLNet.
- Masked Language Model
- Following BERT (Devlin et al., 2019), we replace 15% of tokens with [MASK] symbols, and train the model to independently predict the original tokens.
- Multitask Masked Language Model
- As in UniLM (Dong et al., 2019), we train a Masked Language Model with additional self-attention masks. Self attention masks are chosen randomly in with the follow proportions: 1/6 left-to-right, 1/6 right-to-left, 1/3 unmasked, and 1/3 with the first 50% of tokens unmasked and a left-to-right mask for the remainder
- Masked Seq-to-Seq
- Inspired by MASS (Song et al., 2019), we mask a span containing 50% of tokens, and train a sequence to sequence model to predict the masked tokens.
- For the Permuted LM, Masked LM and Multitask Masked LM, we use two-stream attention (Yang et al., 2019) to efficiently compute likelihoods of the output part of the sequence (using a diagonal self-attention mask on the output to predict words left-to-right).
- We experiment with
- treating the task as a standard sequence-to-sequence problem, where the source input to the encoder and the target is the decoder output
- adding the source as prefix to the target in the decoder, with a loss only on the target part of the sequence.
- We find the former works better for BART models, and the latter for other models.

4.2 Tasks
SQuAD
- an extractive question answering task on Wikipedia paragraphs. Answers are text spans extracted from a given document context. Similar to BERT (Devlin et al., 2019), we use concatenated question and context as input to the encoder of BART, and additionally pass them to the decoder. The model includes classifiers to predict the start and end indices of each token
ELI5
- a long-form abstractive question answering dataset. Models generate answers conditioned on the concatenation of a question and supporting documents.
XSum
- a news summarization dataset with highly abstractive summaries.
ConvAI2
- a dialogue response generation task, conditioned on context and a persona
CNN/DM
- a news summarization dataset. Summaries here are typically closely related to source sentences.
4.3 Results
Performance of pre-training methods varies significantly across tasks
- The effectiveness of pre-training methods is highly dependent on the task. For example, a simple language model achieves the best ELI5 performance, but the worst SQUAD results
Token masking is crucial
- Pre-training objectives based on rotating documents or permuting sentences perform poorly in isolation.
- The successful methods either use token deletion or masking, or self-attention masks.
- Deletion appears to outperform masking on generation tasks
Left-to-right pre-training improves generation
- The Masked Language Model and the Permuted Language Model perform less well than others on generation, and are the only models we consider that do not include left-to-right auto-regressive language modelling during pre-training.
Bidirectional encoders are crucial for SQuAD
- As noted in previous work (Devlin et al., 2019), just left-to-right decoder performs poorly on SQuAD, because future context is crucial in classification decisions. However, BART achieves similar performance with only half the number of bidirectional layers.
The pre-training objective is not the only important factor
- Our Permuted Language Model performs less well than XLNet (Yang et al., 2019). Some of this difference is likely due to not including other architectural improvements, such as relative-position embeddings or segment-level recurrence.
Pure language models perform best on ELI5
- The ELI5 dataset is an outlier, with much higher perplexities than other tasks, and is the only generation task where other models outperform BART.
- A pure language model performs best, suggesting that BART is less effective when the output is only loosely constrained by the input.
BART achieves the most consistently strong performance.
- With the exception of ELI5, BART models using text-infilling perform well on all tasks.
5. Large-scale Pre-training Experiments
- To test how well BART performs in this regime, and to create a useful model for downstream tasks, we trained BART using the same scale as the RoBERTa model
5.1 Experimental Setup
- We pre-train a large model with 12 layers in each of the encoder and decoder, and a hidden size of 1024.
- Following RoBERTa (Liu et al., 2019), we use a batch size of 8000, and train the model for 500000 steps.
- Documents are tokenized with the same byte-pair encoding as GPT-2 (Radford et al., 2019).
- Based on the results in Section §4, we use a combination of text infilling and sentence permutation.
- We mask 30% of tokens in each document, and permute all sentences.
- Although sentence permutation only shows significant additive gains on the CNN/DM summarization dataset, we hypothesised that larger pre-trained models may be better able to learn from this task.
- To help the model better fit the data, we disabled dropout for the final 10% of training steps. We use the same pre-training data as Liu et al. (2019), consisting of 160Gb of news, books, stories, and web text.
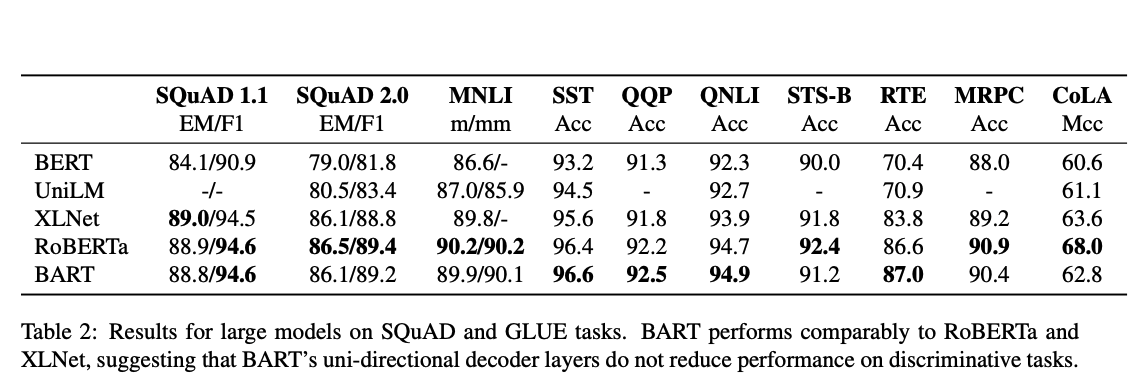
5.2 Discriminative Tasks
- Overall, BART performs similarly, with only small differences between the models on most tasks.
- Suggesting that BART’s improvements on generation tasks do not come at the expense of classification performance.
5.3 Generation Tasks
- BART is fine-tuned as a standard sequence-to-sequence model from the input to the output text.
- During finetuning we use a label smoothed cross entropy loss (Pereyra et al., 2017), with the smoothing parameter set to 0.1.
- During generation, we set beam size as 5, remove duplicated trigrams in beam search, and tuned the model with min-len, max-len, length penalty on the validation set (Fan et al., 2017).
Summarization
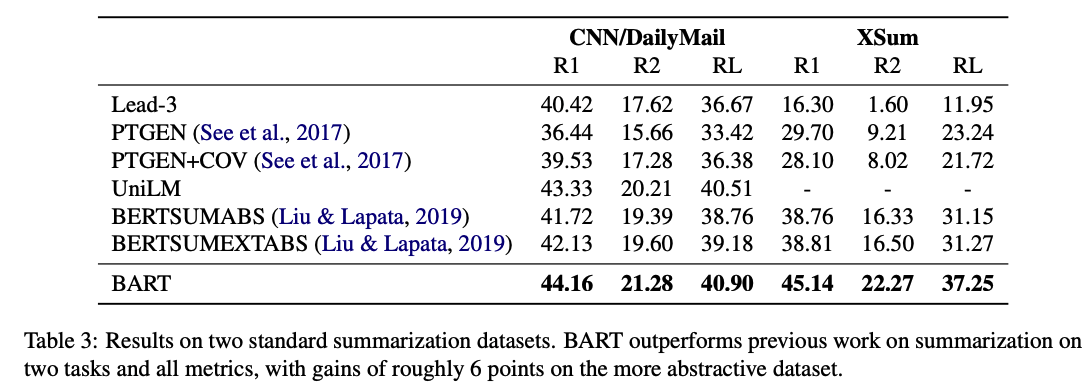
- Summaries in the CNN/DailyMail tend to resemble source sentences. Extractive models do well here, and even the baseline of the first-three source sentences is highly competitive. Nevertheless, BART outperforms all existing work.
- In contrast, XSum is highly abstractive, and extractive models perform poorly. BART outperforms the best previous work, which leverages BERT, by roughly 6.0 points on all ROUGE metrics—representing a significant advance in performance on this problem.
Dialogue

- We evaluate dialogue response generation on CONVAI2 (Dinan et al., 2019), in which agents must generate responses conditioned on both the previous context and a textually-specified persona. BART outperforms previous work on two automated metrics.
Abstractive QA

- We use the recently proposed ELI5 dataset to test the model’s ability to generate long freeform answers. We find BART outperforms the best previous work by 1.2 ROUGE-L, but the dataset remains a challenging, because answers are only weakly specified by the question.
5.3 Translation

- We also evaluated performance on WMT16 RomanianEnglish, augmented with back-translation data from Sennrich et al. (2016).
- We use a 6-layer transformer source encoder to map Romanian into a representation that BART is able to de-noise into English, following the approach introduced in §3.4.
- both steps of our model in the fixed BART and tuned BART rows.
- experiment on the original WMT16 Romanian-English augmented with back-translation data.
- We use a beam width of 5 and a length penalty of α = 1.
- Preliminary results suggested that our approach was less effective without back-translation data, and prone to overfitting—future work should explore additional regularization techniques.
6. Qualitative Analysis
- BART shows large improvements on summarization metrics, of up to 6 points over the prior state-of-the-art.

- Following Narayan et al. (2018), we remove the first sentence of the article prior to summarizing it, so there is no easy extractive summary of the document.
- model output is fluent and grammatical English. However, model output is also highly abstractive, with few phrases copied from the input.
- The output is also generally factually accurate, and integrates supporting evidence from across the input document with background knowledge (for example, correctly completing names, or inferring that PG&E operates in California).
- In the first example, inferring that fish are protecting reefs from global warming requires non-trivial inference from the text.
- However, the claim that the work was published in Science is not supported by the source.
- These samples demonstrate that the BART pretraining has learned a strong combination of natural language understanding and generation.
7. Related Work
- Early methods for pretraining were based on language models.
- GPT : (Radford et al., 2018) only models leftward context, which is problematic for some tasks.
- ELMo : (Peters et al., 2018) concatenates left-only and right-only representations, but does not pre-train interactions between these features.
- GPT2 : Radford et al. (2019) demonstrated that very large language models can act as unsupervised multitask models.
- BERT : (Devlin et al., 2019) introduced masked language modelling, which allows pre-training to learn interactions between left and right context words.
- RoBERTa : Recent work has shown that very strong performance can be achieved by training for longer (Liu et al., 2019),
- Albert : by tying parameters across layers (Lan et al., 2019),
- Spanbert : and by masking spans instead of words (Joshi et al., 2019).
- Predictions are not made auto-regressively, reducing the effectiveness of BERT for generation task
- UniLM (Dong et al., 2019) fine-tunes BERT with an ensemble of masks, some of which allow only leftward context.
- Like BART, this allows UniLM to be used for both generative and discriminative tasks.
- A difference is that UniLM predictions are conditionally independent, whereas BART’s are autoregressive.
- BART reduces the mismatch between pre-training and generation tasks, because the decoder is always trained on uncorrupted context.
- MASS (Song et al., 2019) is perhaps the most similar model to BART.
- An input sequence where a contiguous span of tokens is masked is mapped to a sequence consisting of the missing tokens.
- MASS is less effective for discriminative tasks, because disjoint sets of tokens are fed into the encoder and decoder.
- XL-Net (Yang et al., 2019) extends BERT by predicting masked tokens auto-regressively in a permuted order.
- This objective allows predictions to condition on both left and right context.
- In contrast, the BART decoder works left-to-right during pre-training, matching the setting during generation.
- Several papers have explored using pre-trained representations to improve machine translation.
- The largest improvements have come from pre-training on both source and target languages (Song et al., 2019; Lample & Conneau, 2019), but this requires pretraining on all languages of interest.
- Other work has shown that encoders can be improved using pre-trained representations (Edunov et al., 2019), but gains in decoders are more limited.
- We show how BART can be used to improve machine translation decoders.
8. Conclusions
- We introduced BART, a pre-training approach that learns to map corrupted documents to the original.
- BART achieves similar performance to RoBERTa on discriminative tasks, while achieving new state-of-theart results on a number of text generation tasks.
- Future work should explore new methods for corrupting documents for pre-training, perhaps tailoring them to specific end tasks.




댓글