Abstract
- Autoregressive langaugae models are emerging as the de-facto standard for generating answer
- Previous work on retriever
- partition the search space
- autoregressively generating its unique identifier
- This work generating and score ngrams mapped to candidate passages
- Apply Autoregressive Model on retrieval
1 Intro
- Surfacing knowledge from large corpora
- requires search engine + machine reader component
- Autoregressive langaugae models currently de-facto implementation of the machine reader component
- ;however, has yet to bring similar transformational changes in retrieval approach
- Autoregressive langaugae models on Retrieval
- directly generating evidence given query -> halluccination non-factual content
- generation for query expansion -> does not exploit the full potential of Autoregressive langaugae models
- generatate identifier string for documents (title, root-to-leaf-paths)
- induces structure in search space
- prefix tree 'index' -> valid identifiers generation
- metadata(titles) not available -> hard to apply
- Solutions
- __Search Engines with Autoregressive LMs (SEAL)
- Autoregressive langaugae models(BART) + FM-index

- constrained generation -> preventing generation of invalid identifiers
- FM-index provides information on all documents in corpus containing a specific ngram
- generate any span from any position in the corpus
- novel scoring function : LM probabilites + FM-index frequencies
- matches & outperforms on NQ
- less memory
- intersection formulation SOTA on passage level on KILT
- Autoregressive langaugae models(BART) + FM-index
- __Search Engines with Autoregressive LMs (SEAL)
2 Related Work
Retrieval With Identifiers
- Retrieval approach using autoregressive langaugae models is using identifiers
- titles have been shown to work well as identifiers
-;however, titles not well-suited for retrieval at passage-level does exist (such as containing number of passages) - hierarchical clustering on contextualized embeddeings to create identifiers.
- Contrast to previous works, SEAL identifiers are corpus string matches
Term Weighting
- string-matching-based spsrse retrieval using bag-of-words assumption
- indexing documents with inverted index
- depends heavily on term-weighting schemes
- SEAL generates ngrams of arbitrary size, using the index for both generation and retrieval
Query/Document Expansion
- store documents by generating possible quires that might be answered by them
- augment the query by predicting helpful additional terms
- SEAL boundary between generation and retrieval is blurred since identifiers are grounded passage spans
Query Likelihood models
- query likelihood models using autoregressive models to (re)rank passages according to $P(q/p)$
- probablity of query q given the passage p
- SEAL calculates $P(n/q)$
- probability of ngrams given the query q
Learning to Google
- directly generate search queries for web search engines
- SEAL no black-box retrieval system is queried; instead the white-box index determines both generated ngrams and search spaces
3 Background
FM-index
- gurantee all decoded sequences are located somewhere in the retrieval corpus.
- neither inverted indices nor prefix tress used (not viable options)
- invereted indices : no efficient way to search for phrases of arbitrary length
- prefix : force to explicitly encode all k suffixes in a documents
- Check out below blog post for further details about FM-index
4 Method
- Using FM-index to efficiently find mathcing documents
- Documents are ranked using the scores of generated ngrams
Autoregressive Retrieval
- Get a set of ngrams(K) along with their autoregressivley-computed probabailties according to the model
- autoregressive scoring entails monotonically decreasing scores
- use fixed-length ngranms.
- Each document is assigned the score $$P(n/q)$$$ of its most probable decoded occuring term
- Referred as LM scoring
Factoring in FM-index frequencies
- integrate in scoring unconditional ngram probabilites coumputed as normalized index frequences: $$P(n) = \frac{F(n,R)}{\sum_{d \in R} |d|}$$
- high probability according to the model and low probability according tothe FM-index
- following inspiration from the theory behind TF-IDF and BM25, score function $$w(n,q) = max(0, \log{\frac{P(n|q)(1-P(n))}{P(n)(1-P(n|q))}}$$
- Referred as LM + FM scoring
An intersective Scoring for Multiple Ngrams
- previous socring function
- impossilbe to break ties (only happens when whose highest score ngram is the same)
- difficult to capture all relevant information within a document by considering only a single ngram.
- aggregates the contirbution of multiple ngrams contained in the smae document
- for each document $d \in R$, only consider a subset of generated ngrams $K^{d} \in K$
- An ngram n belongs to $K^{d} \in K$ if there is at least one occurence of another ngram $n$ such that
- $n' \in K^{D}$
- $w(n', q) > w(n,q)$
- document-level score is $$W(d,q) = \sum_{n \in K^{d}} w(n,q)^{\alpha} cover(n,K^{d})$$
- $cover(n,K)$ is a function of how many ngram tokens are not included in the coverage set $C(n,K) \in V$, the union of all tokens in ngrams with higher score
$$cover(n,K) = 1 - \beta + \beta * \frac{|set(n) \setminus C(n,K)|}{|set(n)|} $$ - The purpose of coverage weight is to avoid the overscoring of very repetitie documents, where many similar ngrams are matched
- Referred as LM + FM intersective scoring
5 Experimental Setting
- assess the model by looking at how well the document ranking matches with the ground truth
- feed the documents to trained reader, that uses the documents to generate the answer
5.1 Data
Natural Questions
- dataset containing query-document pairs, where query is is question, and the document is a Wikipedia pages, in which a span is marked as an answer
- NQ_ : retrieval is performed on an entire Wikipedia dump, chunked in around 21M passages of 100 tokens
- accuracy@k : the fraction of instances for which at least one of the top-k retrieved passages contains the answer.
- NQ320k : the retrieval set is limited to the union of all ground truth document in the training, dev or test set.
- hits@k : the fraction of instances for which at least one of the top-k retrieved passages is in the ground truth.
KILT
- Comprehensive benchmark collecting different datasets including question answering, fact checking, dialogue, slot filling, and entity linking.
- All these tasks are solvable by retrieving information from a unified corpus - Wikipedia dump.
- the evidence is usually the paragraph that contains the answer.
- R-precision : a precision-oriented measure that considers only gold dcouments as correct answers, not just any document containing the answer.
5.2 SEAL configuration
Training
- finetune BART large to generate ngrams of length k = 10 from the ground truth documents.
- $|d| - k$ ngrams in a document d, sample(with replacement) 10 ngrams from it, biasing the distribution in favor of ngrams with a higher character overlap with the query.
- add title of the document to the set of training ngrams.
- add different "unsupervised" examples for each document in the retrieval corpus to the training set
- input : a uniformly sampled span from the document
- output : either another sampled span or the title of the pasge
- add special tokens
- a) whether the pair comes from the supervised or unsupervised training paris
- b) whether a title or span is expected as output
Training Hyperparameters
- fintune model with Adam $3*(10)^{-5}$
- warm up : 500, polynomial decay for 8000k updates
- evaluate : 15k steps (early stopping om 5 evaluations)
- label smoothing (0,1), weight decay (0.01) and gradient norm clipping(0.1)
- batches of 4096 tokens on 8 GPUs (512 tokens per GPU)
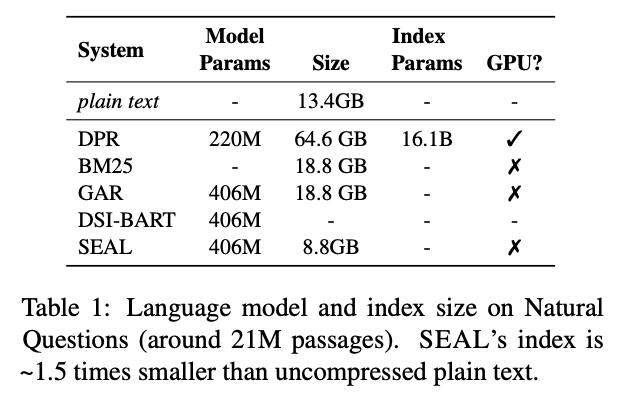
Index
- Each document is encoded as the subword tokenized of the concatenation of the title and the passage, separated by a special token
- 7 times lighter compared to DPR's full document embeddings
- neither need of GPU nor separate storage for the text itself
Inference
- decode for 10 timesteps with beam size of 15
- $\alpha = 2.0, \beta = 0.8$
- constrained decoding stage, we force part of the generated ngrams to match document titles
5.3 Retriever Baselines
- NQ, NQ320k : DSI. NQ320k: GENRE. Otherwise, pyserini BM25
5.4 Reader
- Fusion in Decoder abstractive reader
6 Results
NQ320k
- SEAL outperforms BM25 AND DSI-BART in hits@10.
- SEAL(FM+LM) higher than GENRE
- SEAL(FM+LM instersective)

Natural Questions
- SEAL(LM+FM, intersective) achieves results comparable or superior to more established retrieval paradigms
- achieves the highest performance for question/answer pairs never seen during training, suggesting a better ability to generalize to completely novel quetions with novel answers

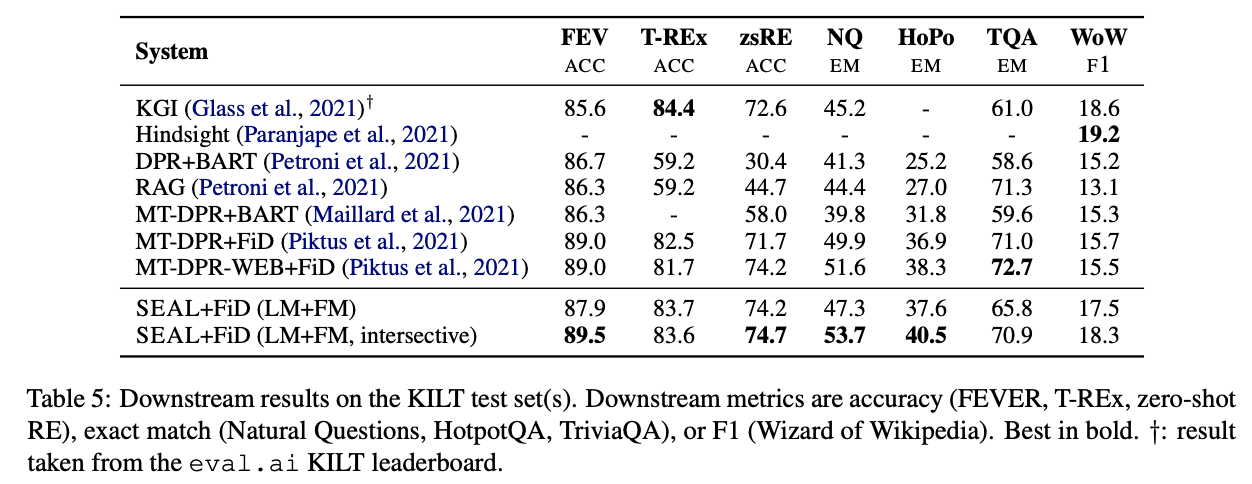
KILT
- SEAL(FM+LM instersective) outperforms previous Retrieval Models

- SEAL(FM+LM instersective) establihes a new state-of-the-art on 4 datasets out of 7
Speed and constrained decoding
- Inference Speed : proportional to the beam search + overahead by constrained decoding
16 and ~ 35 minutes : Slower than GAR(5 minutes), Comparable for DPR(~30 minutes)
Ablation studies
- diminishing returnes encountered between 10 and 15 beam size
- disabling constrained decoding results in slightly lower performances.
Qualitative Analysis
- given query : "can you predict earthquakes?"
- SEAL able to rephrase the query in ways that preserve its lexical material producing ngrams
- generated : earhquakes can be predicted
- SEAL able to explore diverse regions of the output space, overcoming vocabulary mismatch problem
- generated related tokens : seism~, forcast

- generated related tokens : seism~, forcast
Discussion
- SEAL presents solution that could poentially find applications outside information retrieval
- Indexing large corpora with fm-index can be done more efficiently
Conclusion
- SEAL combines autoregressive language model with a compressed full-text substring index
- constraint the generation of existing ngrams in a corpus
- jointly retrieve all the documents containing them.
- SEAL show improvements
- most dataset on KILT
- 4 out of 7 datasets when paired with a reader model
'AI > NLP' 카테고리의 다른 글
| FM-index part4. Wavelet Tree in FM-index (2) | 2022.09.21 |
|---|---|
| FM-index part3. Wavelet Tree (0) | 2022.09.19 |
| FM-index part2. FM-index (0) | 2022.09.16 |
| FM-index part1. BWT (Burrows Wheeler Transformation) (0) | 2022.09.15 |
| Generative Multi-hop Retrieval (0) | 2022.09.12 |




댓글